稚晖君搞了个“好东西”,网上的视频也能拿来训练机器人了 提高复杂任务成功率!上周五,稚晖君在微博预告了一波“好东西”。周一,智元机器人就展示了新产品。这款机器人能够端茶倒水、煮咖啡,还能把面包放进面包机,涂抹果酱,并将面包端到面前。此外,它还可以充当迎宾前台。
不过,这些功能在现今的人形机器人视频中已不罕见。真正值得关注的是智元机器人发布的基座大模型GO-1(Genie Operator-1)。这个大模型解决了人形机器人长期以来面临的数据匮乏和泛化能力差的问题。

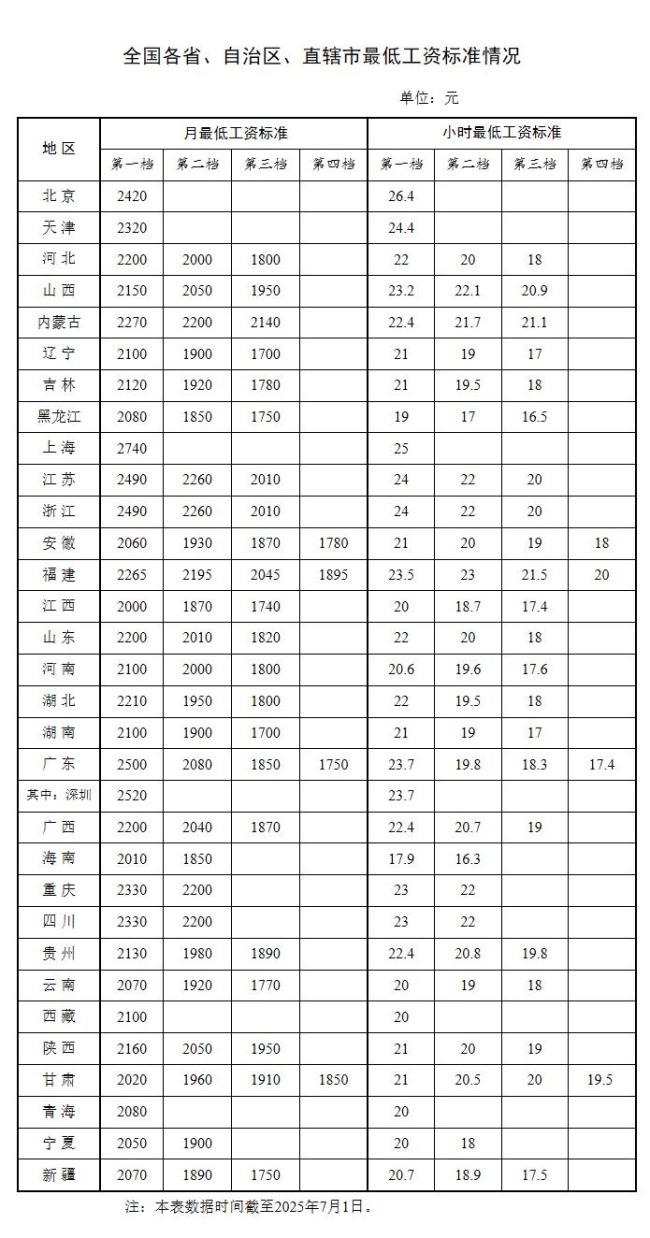
目前,人形机器人表现不佳的一个重要原因就是缺乏高质量数据,而获取这些数据的成本非常高。去年底,智元机器人开源了百万真机数据集AgiBot World,涵盖了超过100万条轨迹、217个任务和106个场景。尽管如此,这些数据仍然不足以解决机器人泛化能力差的问题。
为此,智元机器人提出了新的ViLLA(Vision-Language-Latent-Action)架构,这是GO-1大模型的核心。与传统的VLA架构不同,ViLLA架构不仅依赖于大量标注过的真机数据,还能利用互联网上的大量人类视频数据。这意味着基于GO-1大模型的机器人可以通过观看视频来学习相应动作。
具体来说,ViLLA架构由VLM(多模态大模型)和MoE(混合专家)组成。VLM处理输入的视频数据,潜在动作模型将其拆解成关键步骤,如“抓取”、“移动”和“喝水”。接着,隐式规划器进一步细化这些步骤,生成更详细的指令。最后,动作专家将这些指令转换成机器人可以理解并执行的动作信号。